Measuring Azure OpenAI GPT-4o vs Local LLM Models


Microsoft Build 2024 just concluded last week and one of the highlights was the catch-up release of OpenAI GPT-4o alongside a new hardware line-up of Copilot+ PCs running Windows on ARM with Qualcomm Snapdragon X chips under the hood.
I'll address the huge x86 elephants that were in the room separately. For now, let's focus on the GPT side of things.
Test prepping
Since there aren't local models for GPT-4 and we want to find out which of the available Ollama models are close enough for usage, I proceeded to create new models using the recommended process:

All things to be equal
While all my previous model performance tests for Mistral, Llama 2, Code Llama, and Llama 3 were run using defaults, I decided to normalize the outputs for a balanced chatbot. That means we have to mess with temperature, top_k, and top_p. The default parameter values for Ollama are described in modelfile.md in its GitHub page.

Notice that temperature = 0.8 and top_p = 0.9? These are, accordingly, rather high. While those values would be great out of the box if you were to use Ollama as a chatbot, Llama 3 instruct and derivatives will simply take you for a nice and very long ride if you asked about the sky color. Per the ChatGPT Cheat Sheet these values should be at 0.5. And so, this is what I did for the model file (which can be named anything):

Testbed adjustments
One mistake I did, not reading further enough why it mattered, was not dumping and copying the other parts of the base modelfile. This was easy enough to do for each model that is included in this quick test:
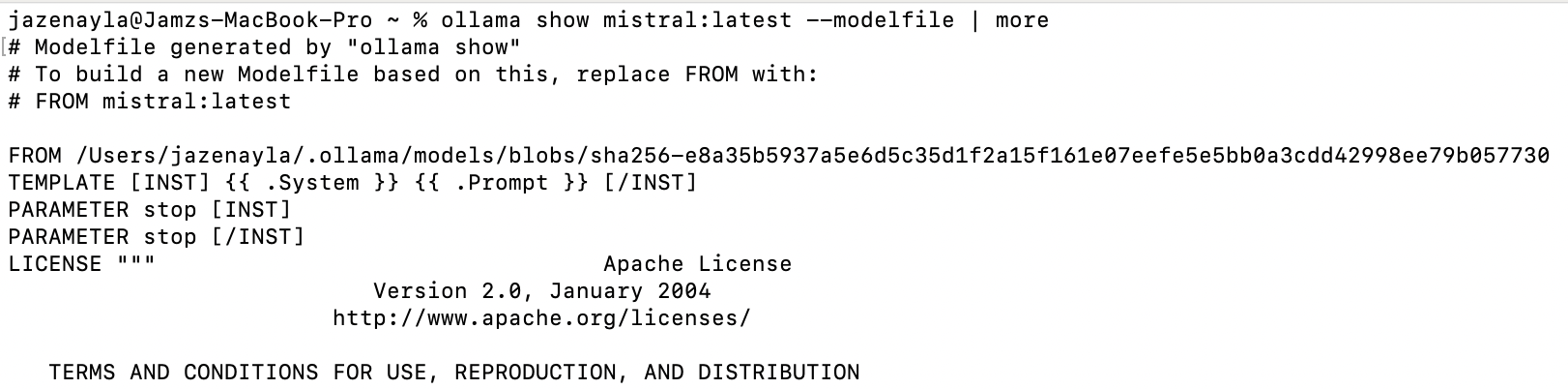
The second mistake, at least in terms of building the modified model, is to refer to the model directly. The correct way, to avoid any confusion, is to refer to the exact path of the downloaded model per the model file dump details. So, all together now:

Making a baseline
And now, for a quick comparative test using Mistral. What is noticeable from the modified model is the lower: total duration, prompt eval duration, eval count and eval duration. Conversely, there is a higher: load duration, prompt eval rate, and eval rate. Also, that explanation seems about 50% shorter than the original. What we can infer from this result is that for Mistral a higher set of parameter values would be better suited to make it less of a text-book like response.


Let's do the same for Code Llama:


Everything in terms of resources is higher, not good? However, take a look at the text details of the verbose results which provides an extra scenario example, that's good as a chatty response. Also, I do like the inclusion of numbers from the base model. Do note that Code Llama is supposed to be built for, ehm, coding. In this case it, also, looks like higher parameters would be more beneficial for this particular model to speed-up the response but would perhaps slightly compromise a slightly more detailed response. We should probably do some code completion tests as a future separate exercise and see what's what.
Local LLMs, all together now!
Alright. Now, let's get the rest of evaluation results across all modified models:






Enter the cloud
Also, here are the results of the same question from Azure OpenAI Playground. To the left is GPT-4 and to the right is GPT-4o:

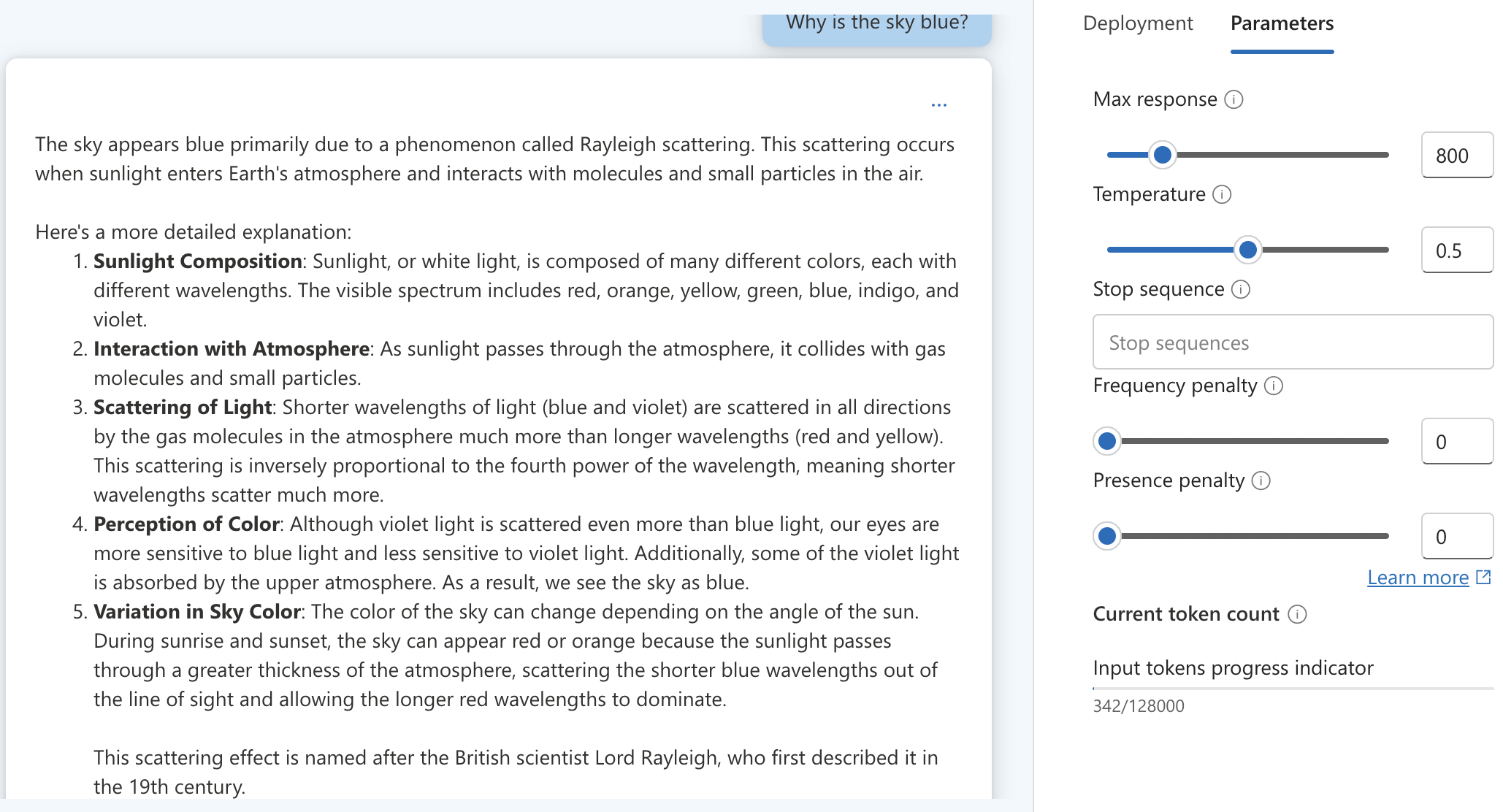
While the responses are quite similar, GPT-4o appears to extract an extra explanation (point #5) by clarifying the answers from (point #3 and #4) of the GPT-4 response.
Here's an extra point, I went all in and raised the temperature = 1.0 and it responded with a slightly terse version. To me, that is like diminishing returns when the results are an almost exact response as from 0.5. See, thus:

The incumbent responds
And, finally, here's the gold-standard comparison itself from none other than OpenAI GPT-4o for Everyone's offer (temperature and other parameters as secret sauce!):

The other guys
For completeness, and because I can for kicks, how about some guest (not their best model foot forward) data comparisons from Google Gemini, Anthropic Claude AI (Sonnet), Perplexity AI, and Meta AI?
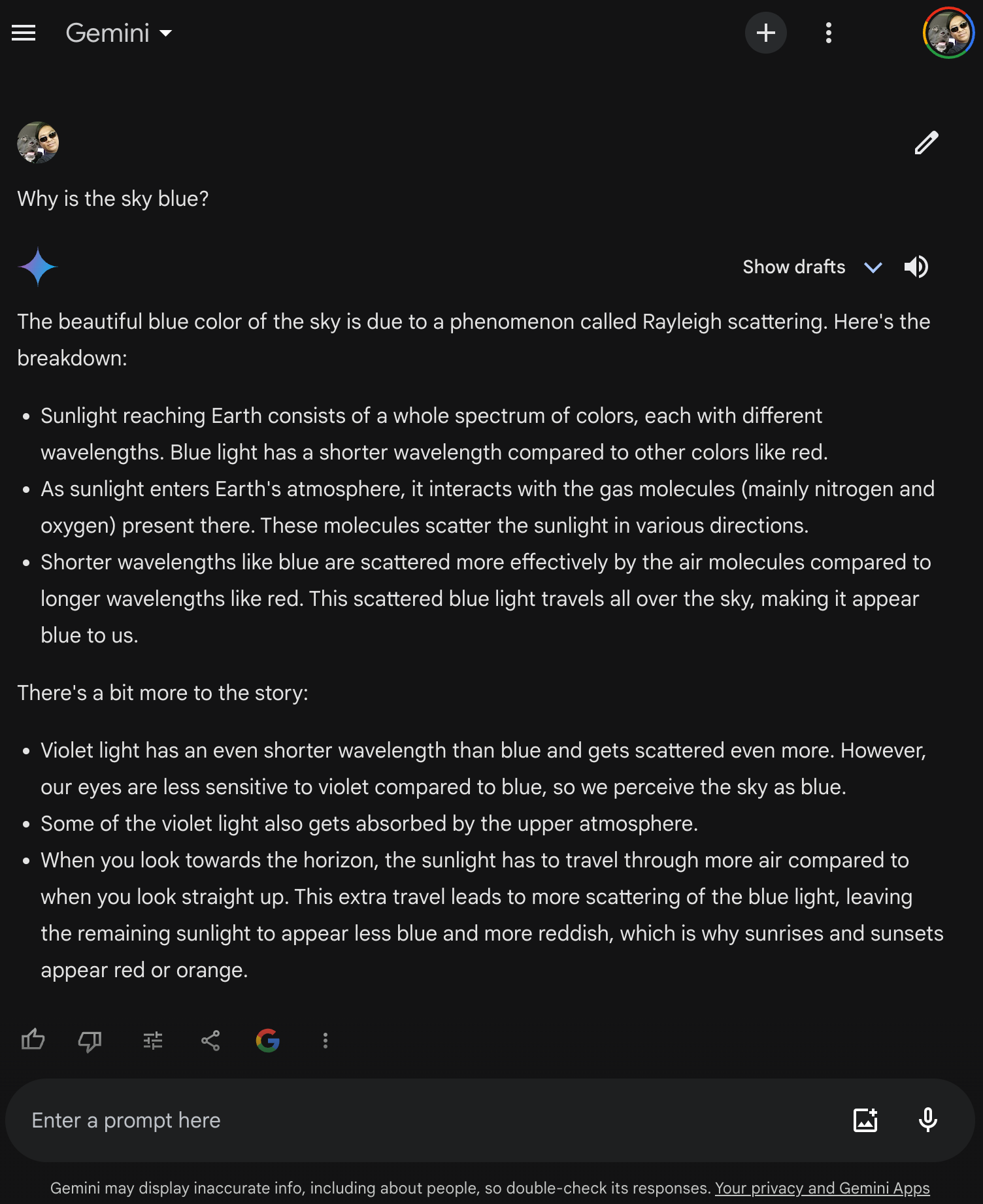

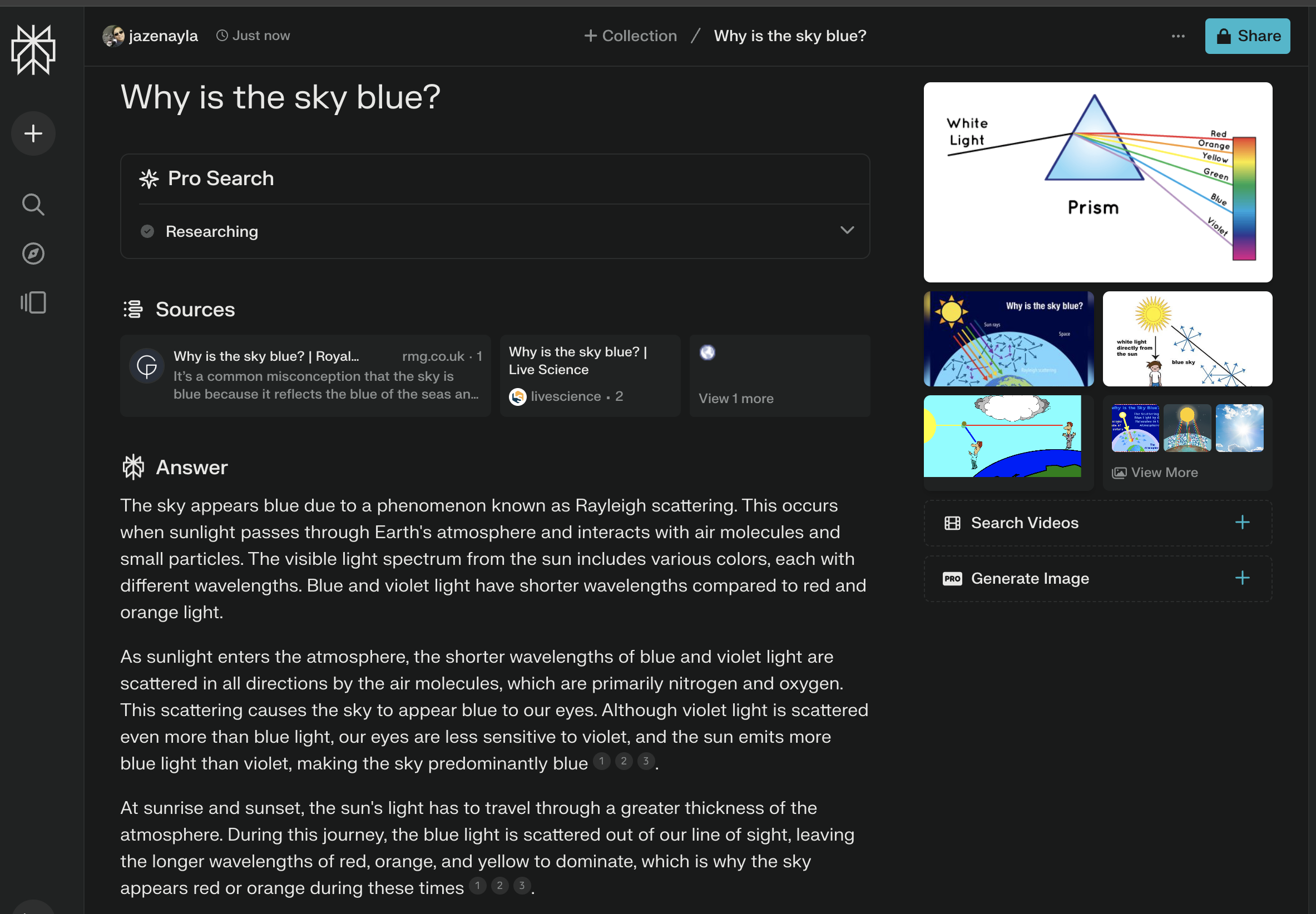
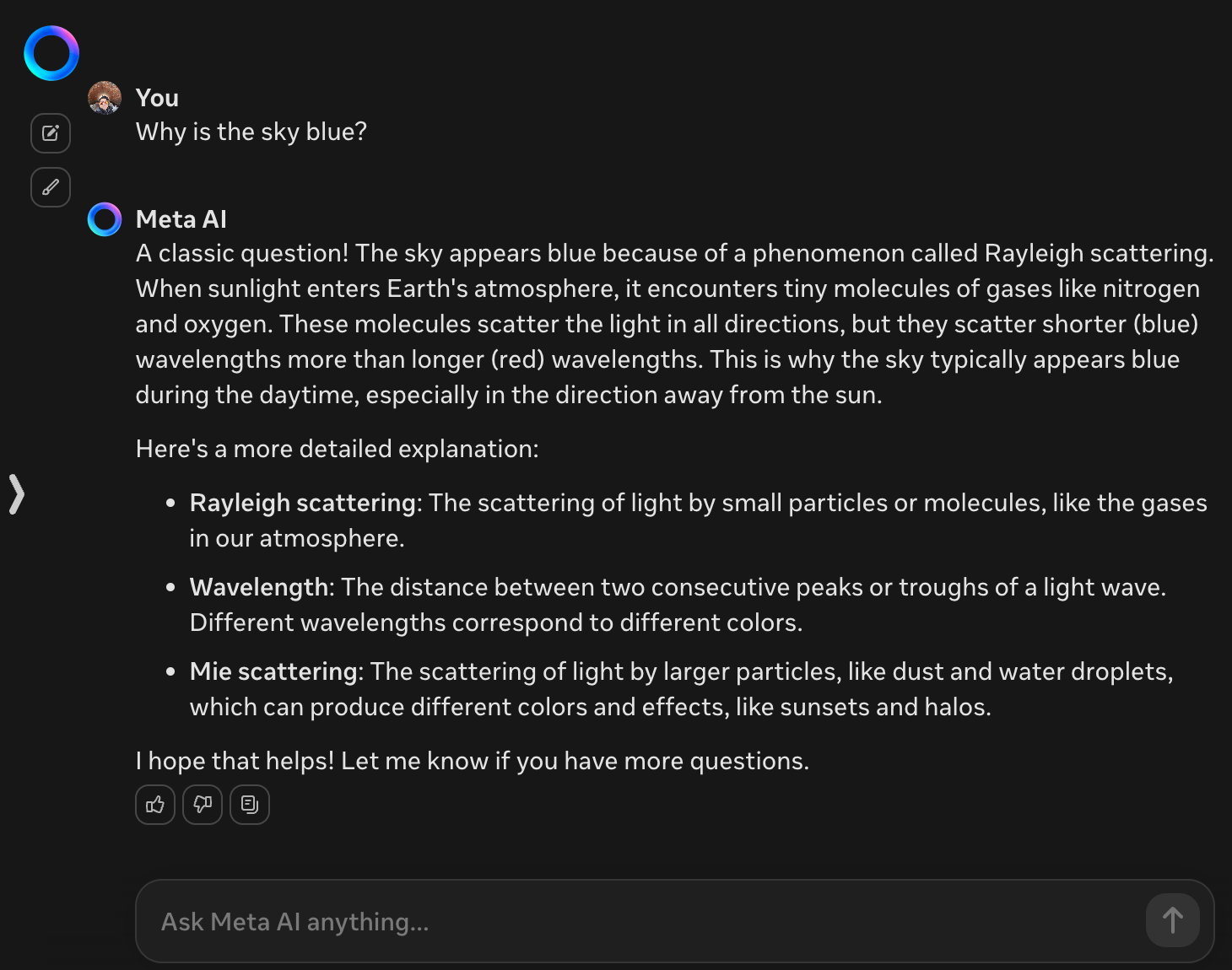
That's the test data. So, let's discuss the results in next part of this blog entry:
What have we learned so far in terms of all the model responses based on this baseline test question: Why is the sky blue?
Updated: 2024-June-03 with Meta AI output