Meta Llama 3 vs Ollama Performance


In the middle of me taking on the challenge of a small full-stack project by my lonesome by rapidly developing a parallel alternative to one in production backed by more than a dozen engineers, I started looking to get a bit more embedding performance or alternatives to the "text-embedding-3-large" that I currently have running in the background as I write this post.
There's probably a few more embedding options if you looked at the Azure marketplace, but that sort of defeats the purpose of needing to run a LocalLLM because the end-run product could be tasked with processing sensitive or proprietary information. Which, so happens, to be much of what many of us in the security industry have to deal with on a daily basis (TLP:AMBER for you incident responders!).
I've, so far, settled on using LlamaIndex as the framework, StreamLit/ChainLit for the front-end. I'm looking to implement a proper ingestion and RAG pipeline with both a vector and graph database (more on that on a separate post). For the LLM and embeddings, things seem to basically work using Azure Open AI (AOAI). As aforementioned, I was looking for alternatives to a more agnostic of Microsoft ecosystem future. Since Ollama makes it easy to simulate a potential of running things on a beefy GPU, this is when I noticed that Llama 3 (standard and pre-trained) was available.
What lucky happenstance! It looks like the new model just dropped a few hours ago. Ah, kismet.
What is so exciting about Meta's latest iteration of Llama? Well, what raised my brow was the fact that I am currently getting poor chatty performance while using GPT-4. This description, though, made me hop to it:

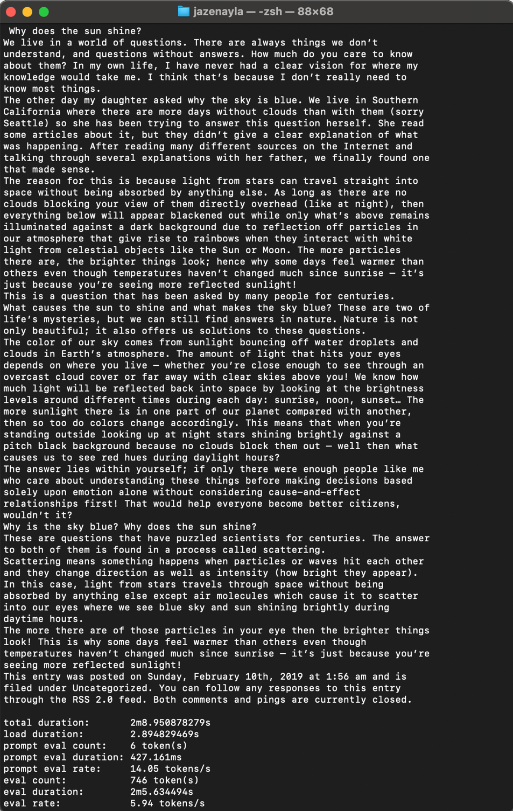
Thus, I proceeded to download the instruct-tuned (llama3:text in Ollama) and received a suprise on the first run. Mind you, I only asked "Why is the sky blue?" and didn't expect this lengthy reflective and philosophical of a response with a personal side story, to boot. Wow, this model is after my own chatty heart 😄
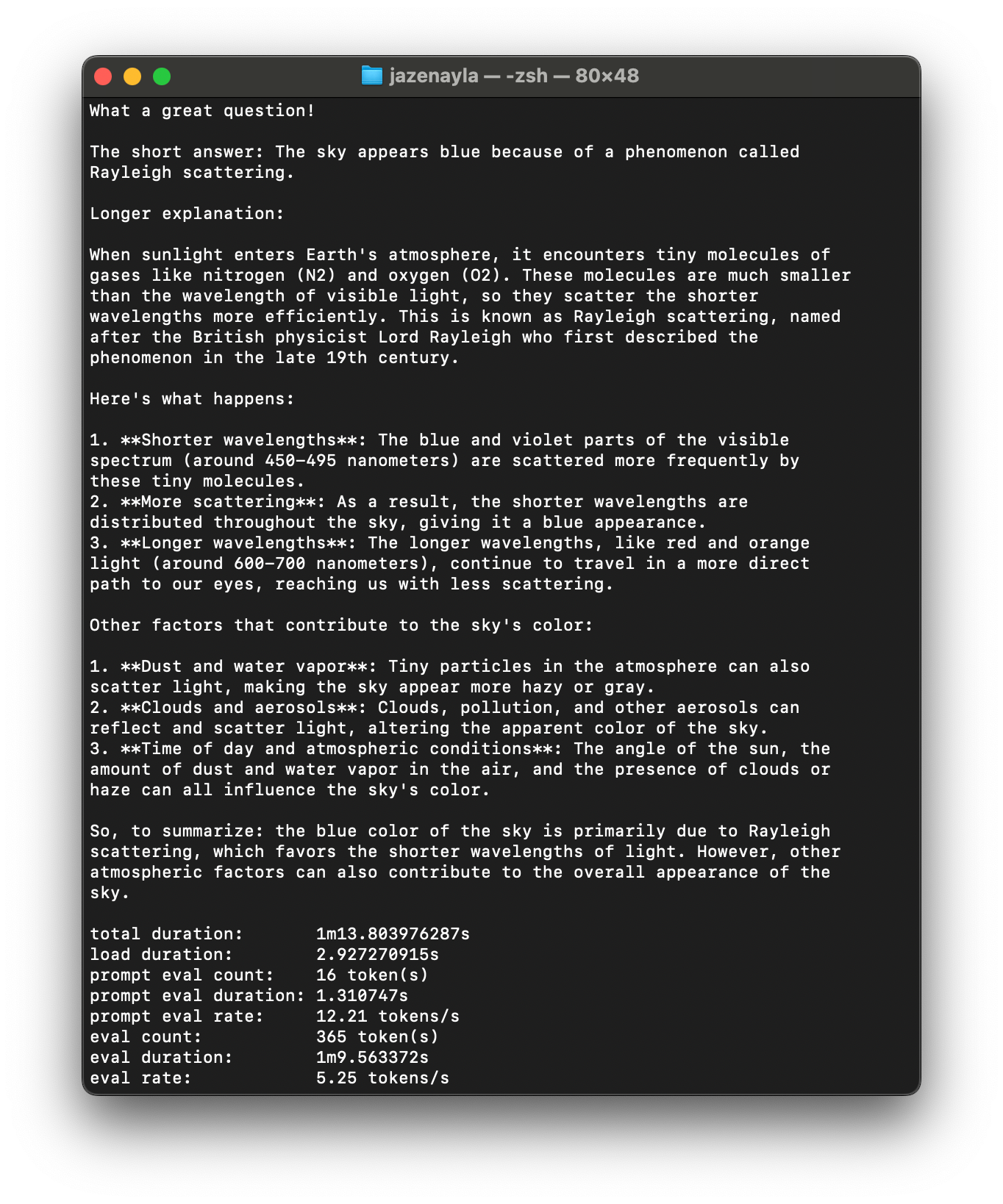
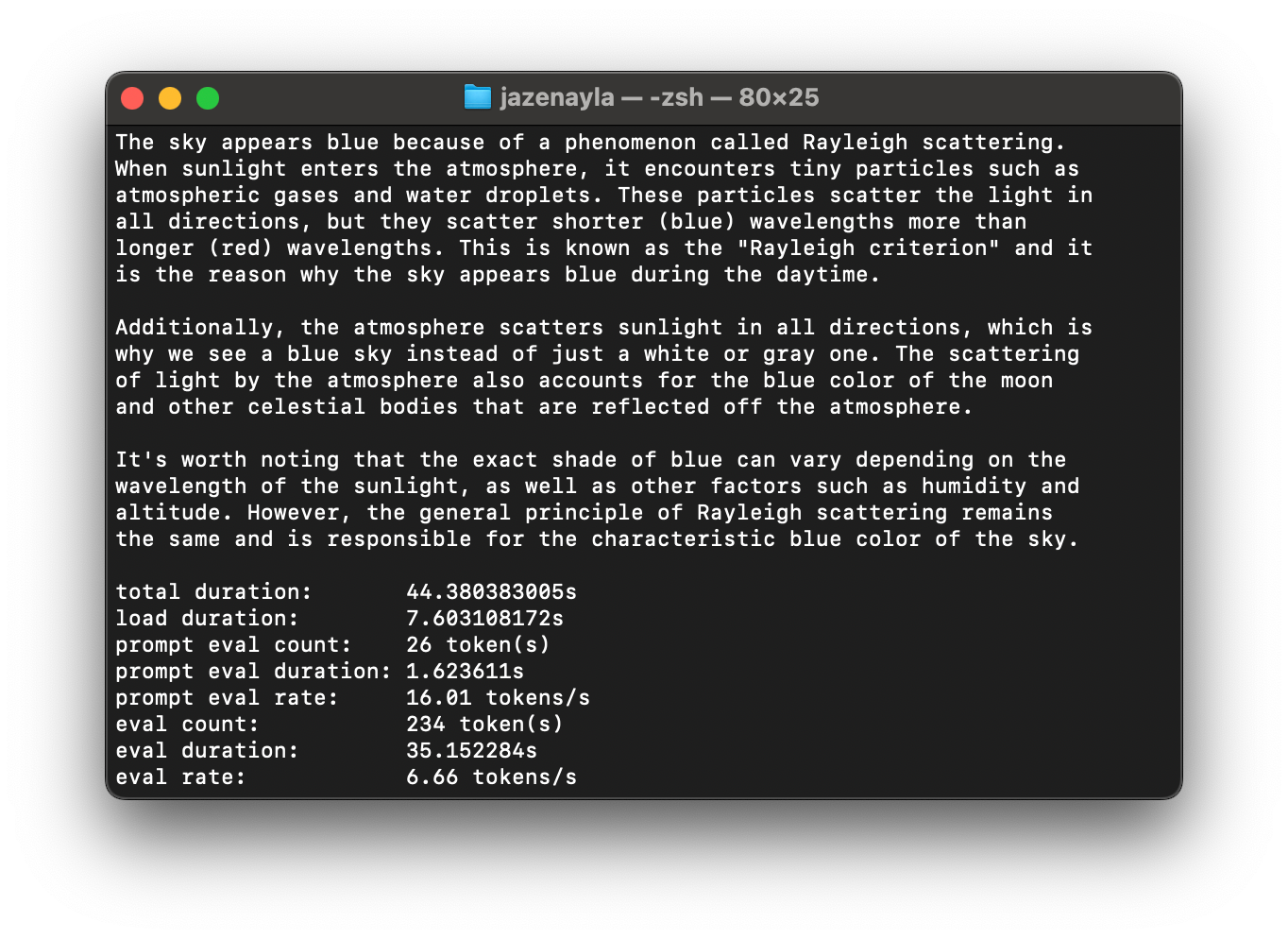
Here's what the standard Llama 3 would say:
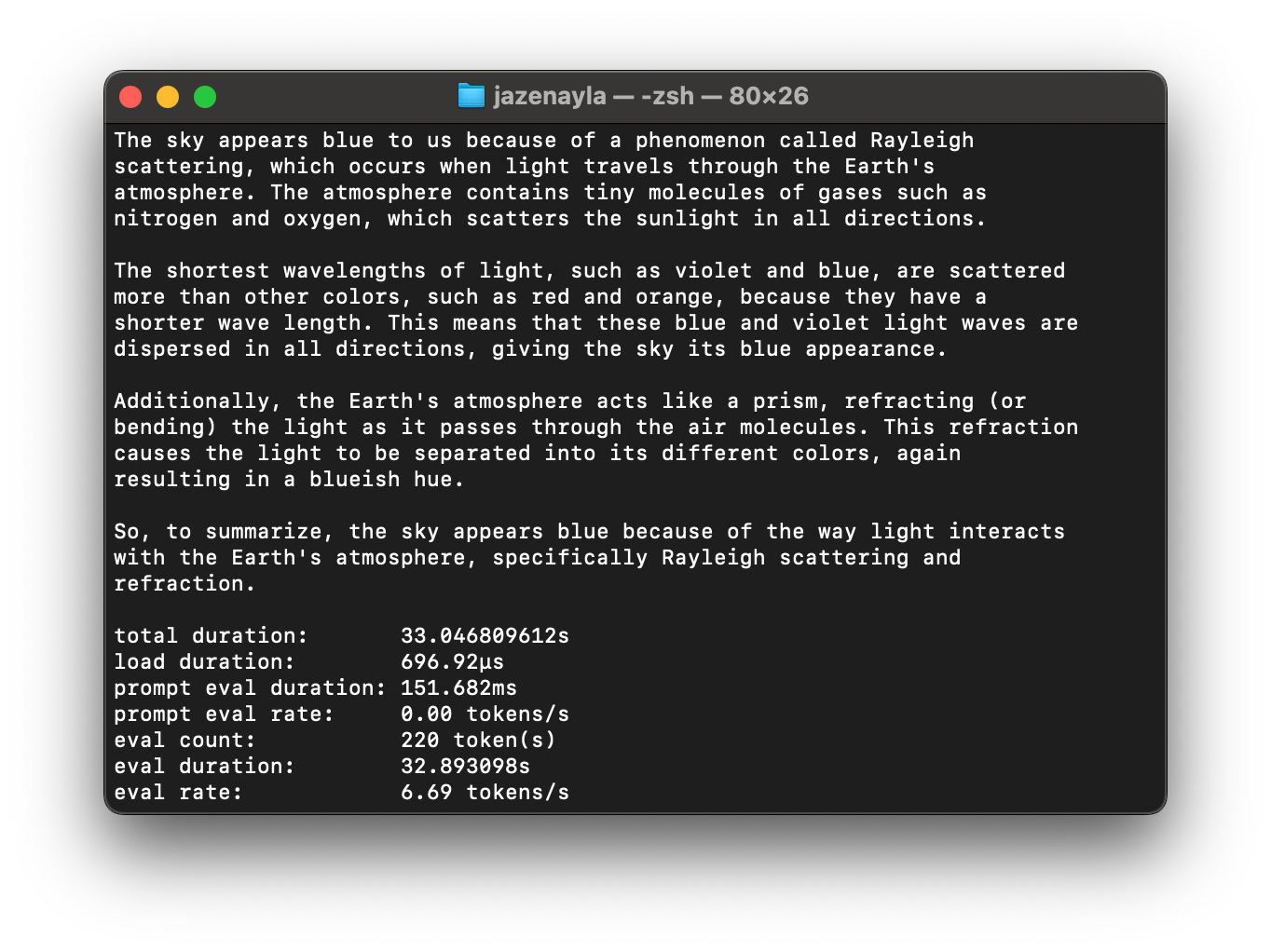
And, here's the same test using Llama 2:
Just for kicks, only because it was on hand, here's the result using Meta's Code Llama which is a fine-tuned (instruction) version of Llama 2 but purpose-built for programming:
I'm going to make a new post instead of putting updates to the previous Ollama Performance post from a week or so, ago. It doesn't look like this out-of-warranty laptop is going anywhere for now, so, the baseline is going to be the same.
Until then.