Summary: GPT-4o vs Local Language Models Evaluation Results


This entry was intended to be Part-2 of my most recent report but realized on review that it is probably the natural follow-up to the other writings on the current state of LLMs (we've not even gone down the road of Small Language Models, yet!) in the first half of 2024. Also, isn't it apt that Star Wars: Episode II is titled "Attack of the Clones"?
Measurement numbers
So, how do we do this?
Let's start with the overall measurements. There performance metrics can be grouped into four-(4) and are described as:
- Total Duration: The total time taken for each model to complete the tasks.
- Load Duration: The time taken to load the model.
- Prompt Eval Count: The number of tokens evaluated in the prompt.
- Prompt Eval Duration: The time taken to evaluate the prompt.
- Prompt Eval Rate: The rate at which tokens are evaluated in the prompt (tokens per second).
- Eval Count: The total number of tokens evaluated.
- Eval Duration: The time taken to evaluate the tokens.
- Eval Rate: The rate at which tokens are evaluated (tokens per second).

Here are two-(2) really good inference measuring articles from Baseten and Databricks. While, there is guidance in terms of hardware, quantization (model re/compression), power, batch sizing, network speed – and the like; remember that we're sort of stuck on some of these given the aforementioned base hardware. Again, thats fine, since this has afforded us a semi-stable baseline to compare things from in this discussion. When and if we need to map it against cloud cost then we can simply make an assumption for apples-to-apples comparison.
Mapping the metrics
Moving on. We're going to concentrate on these specific metrics:
- Time To First Token (TTFT) - When streaming, it is literally how soon users start seeing the first character of a model's output after entering their query. Low waiting times for a response are a must in real-time interactions, but less so obvious in offline workloads. This metric is derived from the time required to process the prompt and then generate the first output token.
- Time Per Output Token (TPOT) - This is amount of time needed to generate an output token for each user that is querying your system. This metric corresponds with how each user perceives the "speed" of the model. This translates to how fast the output is able to be processed and converted to the speed and cadence at which a response displays on screen in milliseconds.
- Words Per Minute (WPM) - In Part-1 of this performance test we used the formula for calculating Words per Minute (WPM) based on Tokens per Second (TPS).
Cost calculations
To estimate the potential cost of running the models based on the data, we need to consider several factors, including the compute time, instance type, and hourly cost of the compute resources. Since the performance metrics such as total duration, load duration, and evaluation duration are known, we can use these to approximate the compute time.
Assumptions: Google Cloud Platform
Instance Type: NVIDIA V100 GPU instance.
Hourly Cost: Approximate cost of an NVIDIA V100 GPU instance is $3/hour.
Total Duration: Includes the load duration and evaluation duration.
Example calculations: myllama2
Total Duration: 56.044795989 seconds
Compute Time (hours): ( \frac{56.044795989}{3600} = 0.01557 ) hours
Cost: ( 0.01557 \times 3.00 = $0.04671 )
When Cost($) is factored-in, however, the sorting goes like this:
- Primary Criteria: Cost (lower is better)
- Secondary Criteria: TTFT (lower is better)
- Tertiary Criteria: TPOT (lower is better)
- Quaternary Criteria: WPM (higher is better)
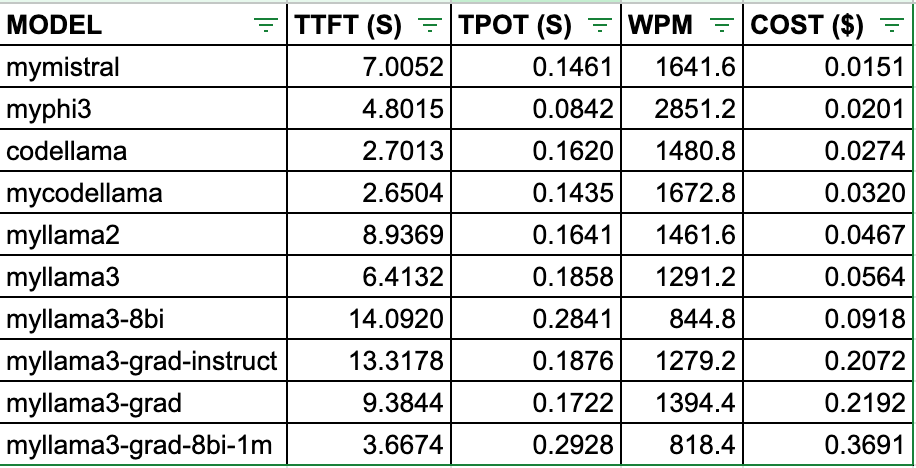
All things considered, Mistral 7B is the most economical with metric performance around the upper third of the pack. This is unsurprising as apart from cost, it's performance when combination with Llama 2B is what used to power Perplexity AI.
Llama 3 and its derivatives rank lower in the cost spectrum. However, that needs to be noted here is that this model shines in the conversational length side of things when temperate and top_p are tuned. I was really impressed by its chat capability the first time I tested this model on Ollama, granted it was at temperature = 0.8
Note that when planning for your particular infrastructure and investment costs to plug-in your current real values to get a more accurate picture!
Overall observations
- Time to First Token (TTFT) in seconds: Lower is better. Code Llama and is the quickest to start generating output.
- Tokens Per Output Token (TPOT) in seconds: Lower is better. Mistral leads in accuracy with 0.1461 tokens per second.
- Words Per Minute (WPM): Higher is better. Phi3 is the fastest in word generation at 2851.2 WPM.
- Cost per use in USD: Lower is generally better. Mistral is the most economical at $0.0151 per use.
- Speed vs. Accuracy vs. Cost: There's a clear trade-off between these factors. For example, Llama3-8bi is the slowest to start (highest TTFT) and generate tokens (highest TPOT), but it's among the more expensive options.
- Performance variations: Llama 3 variants generally have higher costs but show varying performance across other metrics.
- Cost range: Prices range from $0.0151 (Mistral) to $0.3691 (Llama3-grad-8bi-1m) per use.
- Specialized models: Code Llama excel in quick start times, which could be beneficial for certain applications.
Some key takeaways
It keeps being said that this space moves quite fast, but at some point one has to stick a line in the sand to make a start. There is no perfect set to rule them all.
- Parameter tuning has an impact. Playing around with a model's temperature (top_k and top_p) can definitely help optimize for performance and may even save on costs when properly tuned.
- Model characteristics trade-off. Using the right model for the right task will greatly benefit the stage at which it is being implemented. You may want to use a fast response model but be aware its responses could be less accurate.
- Special model capabilities and Diversity. Some implementations try to toe the all-purpose function but it may be more optimal to use a model trained and tuned to a specific task, such as coding or numbers. This could spell a difference in latency output depending on the objective as well accuracy and response veracity.
- Newer model functionality vs Re-work. Some models now allow natively extending capabilities using function calling agents, making it more performant and worth the extra effort to replace a current working model. Consider mixing and matching sections of your flow to use the most appropriate model.
- Cost-efficiency considerations. Sacrificing a little cost to gain better performance could be worth it in the long run. Model training is a different class all itself and while you might get away with using the cheapest it might come back later in having to validate against hallucinations or other unintended artifacts.
In summary, hopefully this set of experiments leads you to a path of using more relevant evaluation questions as these are only a partial list of insights based on the data. Lastly, if you have a possibly larger set of observations that could be true in a specific use case, such as some longer term accuracy observations on a specific domain of knowledge, then definitely make use of it as that will better tune a model or a set of varied working models (recommended) for what you need to accomplish.
Remember, the more you know ... and, that more knowledge is power.