Running Local LLMs on Older Hardware?


As part of this local LLM series, I wanted to know the lower limits of being able to self-host and potentially share demos or development frameworks with my team. Given the acceptable baseline discussion in my previous post, we'll use that to audition the hardware we come across. For testing we don't need creature comforts of a GUI and text chat is acceptable. In that case Ollama is probably one of the most straightforward for us to get things going.
Dell Latitude 5400
Let's start with the spare laptops that I remembered were lying around in the semi-discard pile. On this system I imagined it would be initially sitting at my cube connected to the network and eventually relocated to the server room when fully deployed.

These systems were purchased before the pandemic of 2020 and that kind of makes sense from n Intel Core i5-8365U chip production perspective of Q2 2019.
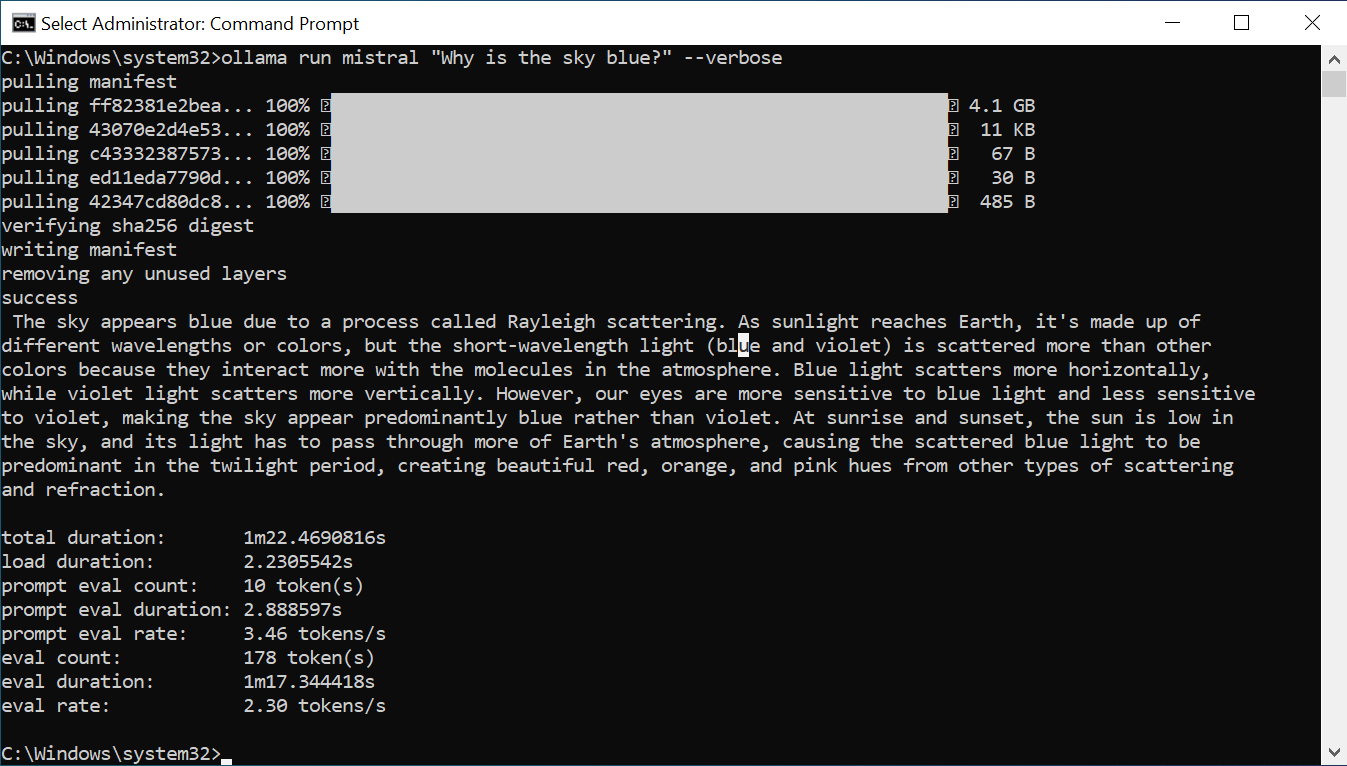
From the low eval rate and the slowness at which the simple response stuttered across the screen, I promptly returned it to the pile.
Hindsight learning, you should consult with an experienced PC builder when purchasing hardware instead of going with default specs. My most recent and oldest system lasted a full decade before decommission due to hardware failure.
Asus P9X79 WS worth three-(3) hardware refresh cycles with 200%+ $$ company savings
Lenovo X1 Carbon (5th Gen)
This is my go-to vacation travel laptop apart from the fact that its technically of no value coming out from 2017 if it sunk under the sea, yet, good enough to let me reach by VPN and allow me to stream my remote watching fix. The X-series is known for the 180-degree opening and water-resistance rating on keyboard splashes.

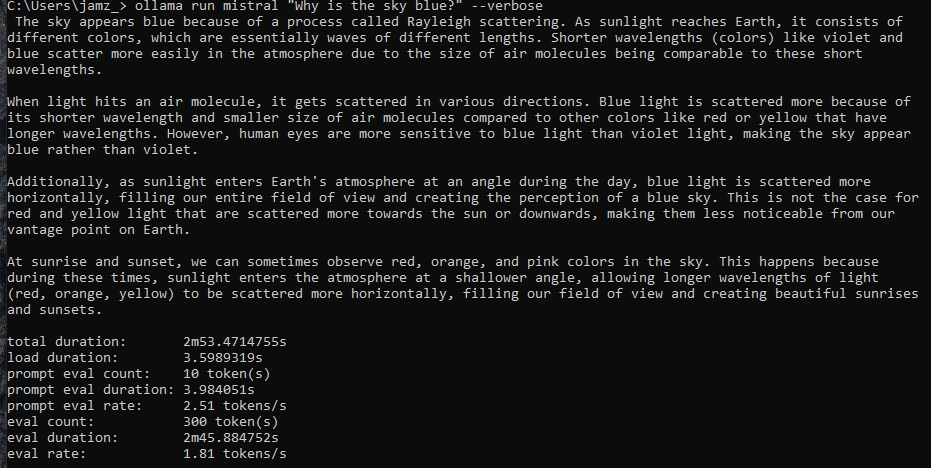
The test results are even worse than the initial spare laptop that is still in service. But, that's to be expected. In reality my Google Pixel 6 Pro or Samsung Galaxy Fold 4 would probably have better stats (and those are mobile phones!).
I'm, also, looking to see if it's even possible to get some local LLM mobile testing going as a separate set of experiments given as ARM chip usage started there, and not the other way around for Copilot+PC. We'll see.
Dell PowerEdge R720xd
This is what I really thought would be worthy of hosting and showcasing all the development frameworks, builds, and demos. There are a bunch of these in the Lab that had replaced era~2006 PE 2950 (Dell Generation 9). Mind you, these "newer" systems are now two-(2) years well past the decade mark and system production for Dell Generation 12 was ~2012 from this month of June 2024. I randomly picked one of them amongst my Proxmox VE high availability cluster set and ran a test:


I really had high hopes for this server given that it is technically had a 16-core Intel Xeon E5-2650 v2 running at 2.6GHz (for a total of 32-threads) loaded with 188-GB of on-board RAM. You can run several production-ready Elastic stacks at 16GB maxed heap (32GB total) and the fact that the Proxmox VE cluster that I configured is running the latest version of Ceph for data redundancy. But, at barely five-(5) tokens/second this isn't going to be a fun multi-user experience.
Hardware to capability
It is important to note that the number of parameters used to train language models and the contents of said parameters are each model developer's secret sauce, the current normal non-critical standard appears to be 7B (7 billion parameters). The trick is how to cram all of that into the smallest size possible (~4GB for most modest hardware), and that is where quantization comes in. HuggingFace has a gentle primer if you want to dig a bit more on 4-bit quantization.
As I've mentioned before, the rate of quantization directly affects the quality of responses. When we say quality, we also mean guardrails against hallucinations (or in common parlance, "making sh*t up").
While improvements in the quality of quantization and fine tuning progresses in parallel, one can only hope those improvements continue to be small enough that last or older-gen hardware can still make use of it.
Ergo, the observations
Per the optimal system requirements of Ollama the above set of hardware examples gets away with the RAM side of things even if they aren't necessarily DDR5.
However, things start to fail on the CPU side because AVX-512 (an extension of Single Instruction-Multiple Data on chip) was only introduced in 2013 and only really got to the server chips past ~2016.
These two-(2) things as hobbled variables are why a ~2012 maxed out server with more cores and RAM appears to trounce a 2017 laptop; but ultimately is as unusable as a 2020 laptop with bare minimum specs.
For all of these reasons and more, the recommendation is to:
- have more than 16GB of DDR5 RAM, and
- a chip manufactured in 2021 or with a lot of cores, plus
- highly recommended, a GPU in the compatibility list
Addendum
There might still be hope!
In the latter part of my IoT/SBC experiments there is an overlooked segment of USB/mPCIe/PCIe/M.2 manufacturers that are creating products that specifically provide the requisite NPU hardware as hardware add-ons. These are potentially of optimal end-user value than a full-fledged GPU (unless you're also planning to do some serious gaming or trying to do some form of digital creation workflow).